Concepts
To explain the core concepts of how Raito works, we’ll start with a highly simplified representation of the Raito model:

- Identities: On the bottom left side, we have the identities, which include users and groups that can request and obtain access to data resources.
- Data Objects: On the bottom right side, we have the available data resources, referred to as Data Objects, to which users can gain access.
- Access Controls: In the middle/top, we have the access controls that define who has access to what.
In the following sections we’ll go deeper into each of these components to explain them in more detail.
All other functionalities (e.g. access and usage insights, access requests etc.) build upon this core model.
Identities
Identities are entities that can gain access to resources. This can be a physical person, a group of people, a service account (i.e. machine user) …
To model these identities, we distinguish several elements in the Raito model:
Identity Stores
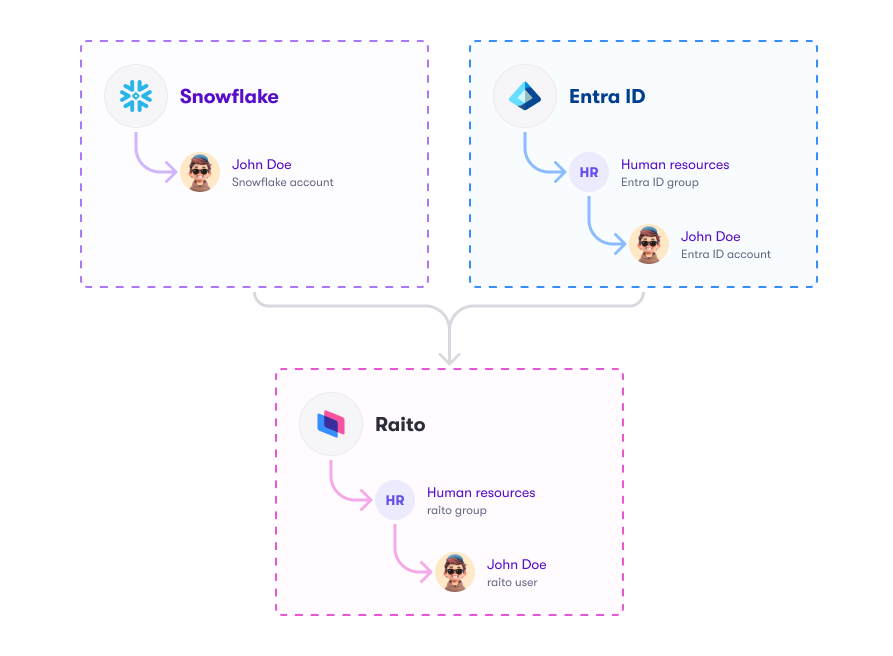
An identity store literally represents a store of identities. It contains accounts and, optionally, groups.
Each data source has one native identity store linked to it, which cannot be changed or removed. This native identity store contains all the identities associated with that data source.
Next to that, also external (standalone) identity stores can be imported (e.g. Okta, Active Directory, …). These can provide additional information about the users. When such an external identity store is linked to a data source, the groups from that identity store can also be used when providing access to objects in that data source.
An identity store can also be marked as master which indicates that this is the main identity store of your company. The groups in this identity store can be used everywhere.
Account
An account is a representation of a user in a single Identity Store.
User
A user is a collection of accounts across multiple Identity Stores (e.g. Snowflake, Azure Entra ID, AWS IAM …), typically representing a single (physical) person or service.
When new accounts are imported into Raito, these accounts are automatically attached to an existing user when the email address matches or to a new user when no user was found with that email address.
An account can be transferred to another or new user manually if needed.
Group
A group is a group of accounts as defined in the identity stores.
Often, groups are defined in an identity management system on the organizational level, like Azure Entra ID or Okta. It is then often logical to use these centrally managed groups to manage access. With Raito, you can leverage these groups to grant access to resources in data sources, even if these groups are not defined in the data source itself.
When access is assigned to a group, Raito will make sure that the users in this group are assigned the necessary permissions and that this remains in sync whenever changes happen to the group.
Data
The data resources represent the entities to which access can be granted and requested.
Data Source
A data source is an instance of a data warehouse, database, reporting tool, …, or any other source of data in your data landscape. Some examples are, Snowflake and BigQuery. You can have multiple data sources of the same type (e.g. multiple Snowflake accounts).
Data sources are the top-level entity to group data objects together.
The data source contains meta data to describe what the data source looks like and how it behaves. For example:
- Which types of data objects exist (e.g. folders, files, tables, …) and which permissions can be set on them
- How is access represented in this data source (e.g. Snowflake is role-based, BigQuery is ACL based, …)
- An explanation of each of the permissions and whether they represent a read, write or admin action
- An indication on which data object level usage metrics should be calculated. Typically, this will be tables and views for data warehouses, files for file systems and reports or dashboards for reporting tools.
This meta data is defined by the connector that is used to synchronize this data source (as we’ll see later). This way, Raito Cloud can easily handle new/custom data source types without requiring an update.
Data Objects
Data objects represent all the data elements that can be found in a specific data source. A data object always belongs to a specific data source.
Data objects are organized in a hierarchy under its data source. For example, for a Snowflake data source, the hierarchy of data objects would look like this: data source > database > schema > table > column.
Access Controls
In Raito, an access control is the abstract representation of ‘who gets access to what’, independent of how this gets implemented in the underlying data source.
Access controls are the only entities that are synchronized in two directions. Existing access controls are pulled in from the data source and access controls that get created and updated in Raito are pushed back to the data source.
This unique bi-directional approach allows you to get insights into your current situation on the first day of using Raito and allows you to start managing access in a more structured way, step-by-step, across all your data sources.
Access controls can look very differently, depending on the data source. For example:
- In Snowflake, a role-based mechanism is used. These roles are assigned to users and users then have to assume these roles to get access to the data they need. In this case, a role in Snowflake gets mapped directly to an access control in Raito.
- In Bigquery (Google Cloud), access is managed by directly assigning users and groups to data objects. This is called an ACL-based (Access Control List) system. When importing, the ACL rules are grouped together to form access controls in Raito. Depending on the specific data source, this can be grouped by user or group, or by data object (+ permission). Defining more properly structured access controls in Raito is then highly recommended. This way, Raito puts an RBAC (role-based) or ABAC (attribute-based) layer on top of the ACL-based system for easier access management.
- In AWS, there are many different ways to managed access to resource, like IAM policies, IAM roles, S3 Access Points, CloudFormation, … Each of these get converted into access controls in Raito.
Access controls that get imported from the data source are marked as Managed in Data Source. This means that, on each synchronization, changes that are made on the data source will be imported again so that these changes are also represented in Raito. The Audit log of this access control will then also show the changes that were made since the last synchronization.
As mentioned, access controls can also be created and edited from within Raito Cloud. You can either create new access controls, or edit imported ones. When editing an imported one, it will go from Managed in Data Source to Managed in Raito. From this point on, changes that are made to this access control in Raito will be pushed to the data source. If changes are still made directly on the data source to this access control directly on the data source, they will not be imported. The exact behavior depends on the type of data source (for example, role-based vs ACL-based).
More information on how to work with access controls can be found in the Access Management documentation.
Access Control actions
To manage access, an access control defines the action that is performs. The following actions are available:
- Grant: this is the most common access control and is used to grant users access to data objects. More information on how to manage grants can be found here. To organize grants better and to configure their behavior, a grant has a Category. More on that below.
- Mask: used to mask the data in the specified columns. These are often referred to as Data Masking Policies. This functionality is only available for data sources that provide support for it. More information on how to manage column masks can be found here.
- Filter: used to filter the rows of a view or table by defining a condition statement deciding wether the row should be available to the user or not. These are often referred to as Row Filter Policies. This functionality is only available for data sources that provide support for it. More information on how to manage row filters can be found here.
Grant Categories
Grant categories are meant to distinguish different types of grants you may want to manage. There is always a default grant category (typically just called ‘Grant’) which is also used to import the access controls that are managed in the data source.
You can configure Grant categories to adapt the Raito UI to your needs.
Some other examples of Grant categories that are typically used:
- Data Product: if you work with data products, you could create a grant category to represent these data products as a grant. This way, your users can easily find the available data products and request access to them.
- Purpose: if you want to implement a Purpose-Based Access Control mechanism, you could create a grant category for this as well.
Inheritance
Access controls can be linked together in an inheritance structure to provide more powerful access management capabilities. Concretely, this means that, when defining the ‘who’ of an access control, you can also point to a Grant (or Purpose) access control. This means that the access control will be applicable for all the users of that Grant as well. For example:
- You define a Mask access control that should be applicable to all users except for the users from a certain Grant.
- You want a Row Filter to be applied for the users of a certain Grant.
- The users of one Grant should also get access to the data defined in another Grant.
Some data sources support inheritance directly (e.g. Snowflake) while other don’t (e.g. BigQuery). In the former case, the inheritance is directly mapped to the inheritance in the underlying data source. In the latter case, the inheritance is flattened to make sure the effect is the same.
Locking
Before, we spoke about access controls being Managed in Data Source or Managed in Raito. In more advanced scenarios, it is also possible to get more fine-grained control over what is managed in the data source and what is managed from within Raito Cloud. The locking mechanism in Raito allows you to lock certain parts of an access control so that they cannot be edited from within Raito Cloud (and are still imported from the data source on each synchronization), while still allowing to edit the other parts (and synchronize them to the data source).
In this case, the access control needs to be Managed in Raito, but in reality it is partially managed in Raito and partially outside.
For example:
- You use Terraform to create Snowflake roles and want to keep doing that as part of your data engineering pipeline. The Terraform script defines what the Snowflake role provides access to, but you want to control ‘who gets access to the role’ in Raito.
- You want to use the Raito dbt integration to automatically create access controls for your newly created data sets, but you want to control ‘who gets access to the role’ in Raito.
- You want to define access controls in Raito Cloud, but already have another tool in place to assign them to users.
- The owners of the access control are managed through tags set on the data source itself and should not be overridden in Raito Cloud.
Different parts of an access control can be locked:
- Who: lock editing the users/groups that get access to the data in the access control.
- Inheritance: lock linking this access control to other access controls using inheritance.
- Deletion: lock the deletion of the access control.
- What: lock editing the data objects that this access control gives access to.
- Owners: lock editing the owners of the access control
Two types of locking are possible:
- User interface locking: in this case the user cannot edit the locked parts of the access control in the Raito Cloud user interface, but it is still possible to edit them through the Raito API.
- Full locking: in this case, the locked parts cannot be edited from the user interface or the API. These parts are only updated by importing them from the data source. This locking is controlled from the Raito CLI (and connector) settings.
The ‘full locking’ functionality is only available for certain data source types. Especially on ACL-based systems this is not possible as the ‘who’ and the ‘what’ are fully coupled.
All locking is configured through the CLI connectors or by using the API.
Tags
To provide more context to entities, Raito supports tags, represented as key-value pairs. These tags are imported from the data sources and identity stores, but can also come from different sources, like a Data Catalog, Dbt, an HR tool …
For example:
- Tags can be set on accounts/groups (which then get inherited by the user they belong to) to define which department the user belongs to, which office/region the user is based at, …
- Tags can be set on data objects to define what type of data they contain. For example:
- A sensitivity classification like PII, PHI, PCI …
- A department indication like HR, Sales, Finance, …
- Tags can be set on access controls to categorize them or define owners.
Tags can be used to define attributes-based access controls, to filter entities during search, to do reporting, …
Usage
Raito will also gather usage information from data sources that support it.
This means that Raito will fetch and store the queries that are done on the data source to read/write data or to change the data structure (like creating a new table, dropping a schema …).
With this information, insights are calculated to bring visibility on who has (not) been using their access and how.
Raito Graph
The Raito Graph is the graph structure that is built inside of Raito Cloud. It contains and interconnects the meta data of all data sources, the users and groups from the identity stores, the access controls, data usage, … This graph allows us to extract knowledge and actionable insights out of all the meta data supplied.