Introduction
The main purpose of the Raito Command-Line Interface (CLI) is to synchronize data between your data sources and identity stores, and Raito Cloud. For this, you can use the run command.
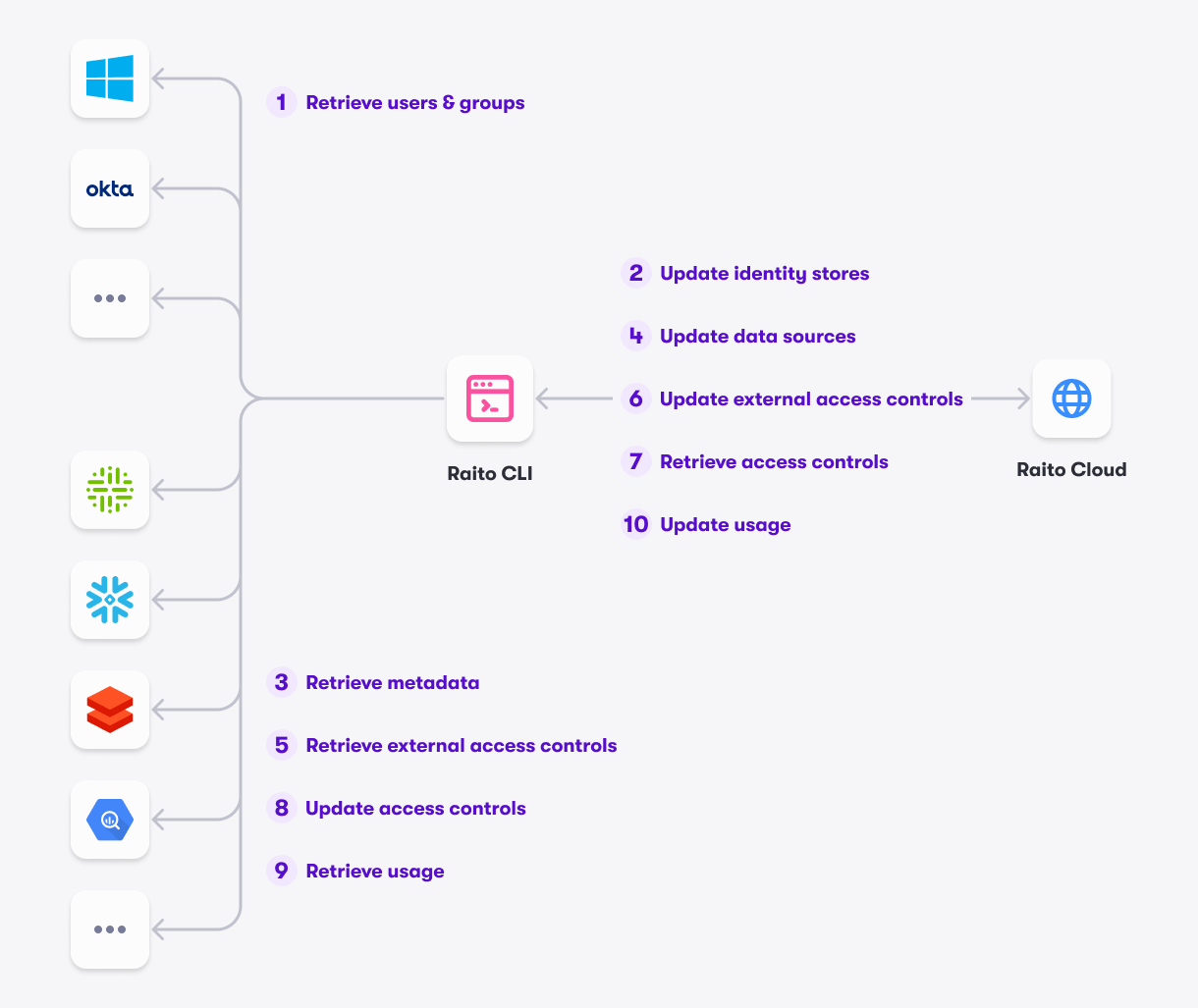 Basically, the run command will execute a list of actions on each of the targets:
Basically, the run command will execute a list of actions on each of the targets:
- Fetch all users and groups from the identity store (e.g. Okta, Microsoft Entra ID, …) or from the data source (which will also have accounts and possibly groups) and synchronize this with the matching identity store in Raito Cloud.
Step 1 and 2 in the picture - Fetch all the metadata from data source (which can be done through a data catalog) and update the appropriate data source in Raito Cloud.
Step 3 and 4 in the picture - Fetch the access controls defined in the data sources and push them to Raito Cloud. This will only look at the access controls that are not managed from within Raito Cloud (see next step). This way a full 360° of all access controls will be available in Raito Cloud from day one.
Step 5 and 6 in the picture - Get the internal access controls from Raito Cloud and update the access controls in the target data source accordingly.
Step 7 and 8 in the picture - Retrieve the data usage information from the data source and push it to Raito Cloud.
Step 9 and 10 in the picture
Target
Targets are the different data sources and identity stores that the CLI will connect with. The logic to interact with the different types of targets is implemented in plugins (also called connectors).
See Target Configuration on how to specify and configure the targets in the CLI.
Connector
A connector is the part of the CLI that connects to a specific target.
For example, the Snowflake connector is used to connect to Snowflake targets.
Connectors are implemented as plugins for the CLI. A connector plugin is basically a small application, implementing a specific API to make sure the CLI can communicate with it to execute the necessary target-specific work (e.g. fetch the Snowflake metadata or push the access controls to Snowflake).